

For the past years, I’ve been challenging myself to solve the Advent of Code challenges in the most cumbersome ways: Using a different language each day or by using only C/C++1. Last year, I originally didn’t want to participate at all as I had a lot to do at work and little time to spare. But as I left for the christmas holidays, I finally had some time to unwind from thinking about compilers all day. And then it hit me: Couldn’t I just solve every task by writing a compiler?
Now hear me out! Of course, strictly speaking a program reading arbitrary text to produce a number or string2 are hardly a compiler. On the other hand, the compiler alignment chart (sourced from the dead bird site) would beg to differ:
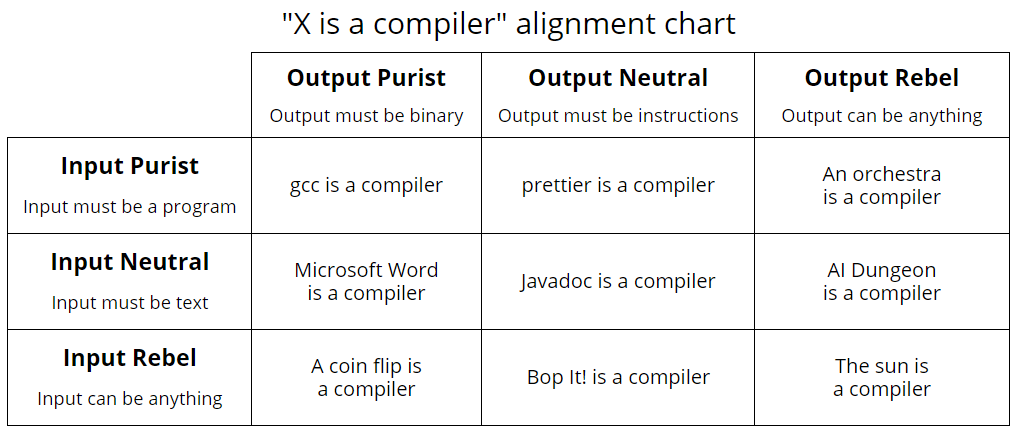
But it’s true, effectively we only need the compiler frontend, i.e. a parser, since most tasks mainly revolve around parsing and processing input. So my challenge for this year was: Solve this year’s Advent of Code challenges by only writing parsers.
The Tools
For a stupid challenge like this, it only made sense to use something arcane for implementing the parser: flex and bison.
Both are by now tried and tested tools for writing parsers and lexers, respectively.
And, true to the spirit of the challenge, they generate C or C++ code, even though the latter doesn’t compile.
But how does my self-inflicted tech stack work? Let me give you an overly long (but still overly simplified – please don’t roast me, dear colleagues) primer on parsing input the proper way (using C and flex+bison).
A Running Example
One of this years’ tasks that can most obviously be solved using a parser is Day 10’s CPU instruction interpreter.
As part of the story, you have to fix up your broken handheld communication device after falling into a river.
To do that, you have to understand the assembly instructions given off by it.
The CPU has exactly one internal register X and features 2 operations:
addx val: modifies the internal register by adding the value to it. This operation takes 2 cycles to complete.noop: sleeps for one CPU cycle.
The first task is then to take your puzzle input in the form of a bit over 100 lines of instructions and parse it. You are supposed to take the register contents during the 20th cycle, multiply it with the cycle count and repeat the process every 40 cycles. All results then have to be summed to form your solution.
Simplifying the Input
So let’s just chuck our input into the parser, right? Wrong.
While you could do that, that’s not how most parsers are intended to be used. Why?
Because you use a parser only to assign meaning to your input by matching it to certain rules.
To simplify this step, a commonly employed tool is the lexer.
It takes an input character stream and maps individual strings (which are called lexemes in this context) to tokens (or syntax errors3).
This allows us to write a parser later on that directly operates on the emitted tokens.
Tool of our choice for this step is flex, a true jewel from the 80’s that nicely integrates with our parser.
Normally, you design the lexer and parser side-by-side, but let’s take things step by step. A piece from our input may look like this:
addx 7
noop
addx 1
addx -33
noop
Every input possibly encountered by the lexer must be described using a rule, otherwise we’ll run into errors. First, we define a few shorthands (full source file here) which we can then use in our lexing rules (for small examples like this it’s a bit overkill but at least it’s good style):
NOP "noop"
ADD "addx"
NUM [0-9\-]
NL [\n]
SPACE " "
Our input is mainly comprised of our two operations, addx and noop, combined with some numbers as arguments.
Since the operations will have a semantic meaning later, we separate them from other inputs by defining them as special strings.
Other than that, we have NUM, which matches all numbers between 0 and 9 as well as a -, since inputs may be negative as well.
Finally, we need to also match newline characters and spaces, since both are part of our input as well.
With these definitions, we can then turn to our rules for matching recognized inputs to tokens which shall be emitted:
{NOP} { return NOP; }
{ADD} { return ADDX; }
{NUM}+ {
int num = atoi(yytext);
yylval->num = num;
return NUM;
}
{NL} { return NEWLINE; }
{SPACE} { /* we ignore spaces */ }
<<EOF>> {
return END_OF_FILE;
}
. {
printf("[error] Encountered unexpected token %s\n", yytext);
return 0;
}
The rules always define on the left-hand side an input to match on and in braces on the right the action to take (as C code).
For NOP, ADD and NL, these actions are straightforward, we just emit a token of the name.
For numbers, the process is a bit more difficult.
We don’t just want to emit a token saying a specific input class was read, we also want to transmit the number itself.
For that, we match on {NUM}+, one or more connected items of the NUM class we defined earlier.
Then, we parse the number using standard C facilities.
Note, that yytext is a variable exposed by flex itself.
It contains the character string that matched the rule on the left-hand side.
We then assign the parsed number to yylval.
But where are the tokens we emit and the yylval variable defined?
Well, they’re both coming from the parser file in bison and must be defined there.
This is, in my opinion, one of the great hurdles when starting out with these tools: They are so deeply intertwined that learning them can result in a lot of headaches as things usually don’t work as you expect them to at first. For example: I originally tried to use C++ this time for at least some Quality of Life improvements over pure C. But alas, the C++ parser and lexer didn’t want to work together and even the official examples didn’t compile for me. So I buried the idea quickly after sinking hours into the debugging process.
The last rules in our lexer declare that we ignore any spaces (we’re not in Python after all) and want to match on the end of file as well, to know when lexing is done. The final rule matches on all remaining lexemes and emits an error message to inform the user of a syntax error occuring.
With that, we defined the lexer appropriately. The full file (containing all set-up instructions and options) can be found here.
Bring in the Grammar!
If reading that section heading gave you bad flashbacks to your language lessons, don’t worry. If it gave you flashbacks to your formal systems lectures, I have bad news. Job of a parser is to assign semantics to the tokens we produced in the previous step, and these semantics are expressed using a formal grammar.
In simple terms, such a grammar is composed of different rules that describe any legal structure of the input. So, going back to our CPU instruction parser example, the grammar would look like this:
<input> ::= <line> <input> | END_OF_FILE
<line> ::= <instruction> NEWLINE | NEWLINE
<instruction> ::= NOP | ADDX NUM
The syntax you’re looking at is called “Backus-Naur form” (BNF) and chances are you’ve learned about that if you ever attended a lecture on formalization of languages. The left side of each rule is called a nonterminal, the symbols in CAPS are terminals or just tokens. As the name suggests, nonterminals are themselves just placeholders for other grammar rules. You can think of them as variables or modules that allow you to stick together a grammar.
In our example, we want to parse an arbitrary number of input lines, each containing a single instruction.
This is represented by the rule in line 1, the starting rule for our grammar.
It says that each input instantiation consists either of a line rule followed by another input rule or an end-of-file token (the OR is indicated with a pipe symbol).
This allows us to read as many lines (i.e., instructions) as we want.
The <line> rule defines that each line may contain exactly one instruction and is terminated by a newline, allowing for empty lines (I did that because copying the input file adds an empty line to the file at the end).
Our final rule defines different types of instructions, in our case NOP or ADDX NUM, the only two operations we need to support.
And that’s it, that is our grammar.4
Now we can obviously start writing an absolute unit of an if-else chain matching this grammar in our program and post it to r/shittyprogramming.
But, as you might have guessed, the problem of “parsing things” has been solved a long time ago and there exist solutions that don’t want to make you pull out your hair in agony.
So, we lay our eyes upon the holy grail that has been gifted to us by Richard M. Stallman himself5: bison.
GNU Bison is a parser generator that allows us to give it a grammar definition written in BNF, from which a parser is generated.
The choice for this tool was mainly motivated by the fact that I used both flex and bison in the past to implement my own shell6.
Numerous parser algorithms exist that all have individual benefits and drawbacks, but discussing them in detail would be a bit much. It’s enough for us to know that Bison generates a LALR(1)7 parser. In case you’re not familiar with that, let us just keep the following in mind: Our parser will work left-to-right, meaning it processes our input in the order we feed it into the parser. The nice thing is, that we don’t have to care about what happens under the hood of the parser, except for when our parser fails for dubious reasons.
Writing the Parser
Ok, so now that we have digested the core concepts of what a parser does, let’s get back to the code.
As I said before, bison integrates nicely with flex.
It expects a function called yylex that returns the next token for the parser to process.
Normally, you could also implement the function itself, but we have a dedicated lexer for that.
And the neat thing is, that flex generates this function already based on our definitions, we can simply import the generated lexer in the parser definition.
For the parser itself, we can now think about how to solve the task we were given.
We don’t just have to read the instructions, we must also interpret them, store the register contents and sum them at specific points.
So, it’d be nice if we could invoke specific actions for some grammar rules and keep some sort of internal state.
Luckily, both things are possible.
To keep an internal state for the parser, we just define a corresponding struct (which I just named parser_state for convenience) in the header file that will be generated:
// parser.y
// Code for the header file generated by bison
%code requires {
struct parser_state {
/// Program Counter
size_t cycle;
/// Contents of register X
long reg;
/// For solving task 1
long sum;
/// keeps track of the next CPU cycle.
size_t next_target_cycle;
};
}
Additionally, we put a function in the generated C file that takes care of incrementing our program counter and summing the register values:
// parser.y
// Code for the c file
%{
#include <stdio.h>
#include <stdlib.h>
#include "parser.h"
#include "lexer.h"
void increment_cycle(struct parser_state *state) {
state->cycle++;
if (state->cycle == state->next_target_cycle) {
long tmp = state->cycle * state->reg;
printf("[info] Register contents at cycle %zu: %ld\n", state->cycle, state->reg);
state->sum += tmp;
if (state->next_target_cycle < 220) {
state->next_target_cycle += 40;
}
}
}
%}
With these functionalities in place, we can now define the real grammar of the parser, similar to the BNF definition we saw above.
For that, we first need to define the tokens we already used in the lexer (and which are imported from the parser, so both files have a symbiotic relationship).
You will see that we can attach values to specific tokens.
This allows us for instance to store the parsed number alongside the NUM token.
As a neat bonus, bison allows us to define actions (i.e., code) to be executed as part of reading a rule.
We use that to increment the CPU cycles and handle the register value addition:
// parser.y
%union {
int num;
}
%start input
%token NEWLINE
%token NOP ADDX
%token <num> NUM
%term END_OF_FILE
%%
input
: line input
| END_OF_FILE { return 0; }
;
line
: instruction NEWLINE
| NEWLINE
;
instruction
: NOP { increment_cycle(state); }
| ADDX NUM {
increment_cycle(state);
increment_cycle(state);
state->reg += $2;
}
;
As you can see, the rules look similar to the ones we defined before.
And that’s it already, there is our grammar to parse the whole task and solve part one automagically while processing the input.
We of course need some more setup code which you’ll find in the complete parser.y file here.
The last part we have to take care of is invoking the parser.
But now, that’s as easy as pie.
We just write a quick main function at the end of our bison file that initializes our state and the lexer and runs the parser to end by invoking yyparse with the necessary arguments8:
int main(void) {
struct parser_state *state = calloc(1, sizeof(struct parser_state));
if (!state) {
fprintf(stderr, "\033[91m[error] Ran out of memory\033[0m\n");
return EXIT_FAILURE;
}
state->reg = 1;
state->next_target_cycle = 20;
// initialize the flex scanner
yyscan_t scanner;
if (yylex_init(&scanner)) {
fprintf(stderr, "\033[91m[error] Could not initialize lexer\033[0m\n");
return EXIT_FAILURE;
}
if (yyparse(state, scanner)) {
// error during parse occured
return EXIT_FAILURE;
}
// de-initialize the flex scanner
yylex_destroy(scanner);
// task 1
printf("Sum of signal strengths: %ld\n", state->sum);
free(state);
return 0;
}
The Bottom Line
So in the end, the following steps happen in our lexer-parser combo: We feed the lexer our original input:
addx 7
noop
addx 1
addx -33
noop
Which will turn it into a stream of tokens that looks like this:
ADDX NUM(7) NEWLINE NOP NEWLINE ADDX NUM(1) NEWLINE ADDX NUM(-33) NEWLINE NOP NEWLINE END_OF_FILE
Then, our parser matches these tokens following our rules, starting with the input rule, as it is defined as the starting symbol.
The result is a derivation of our grammars’ rules, a so-called parse tree (please forgive my non-existing drawing skills):
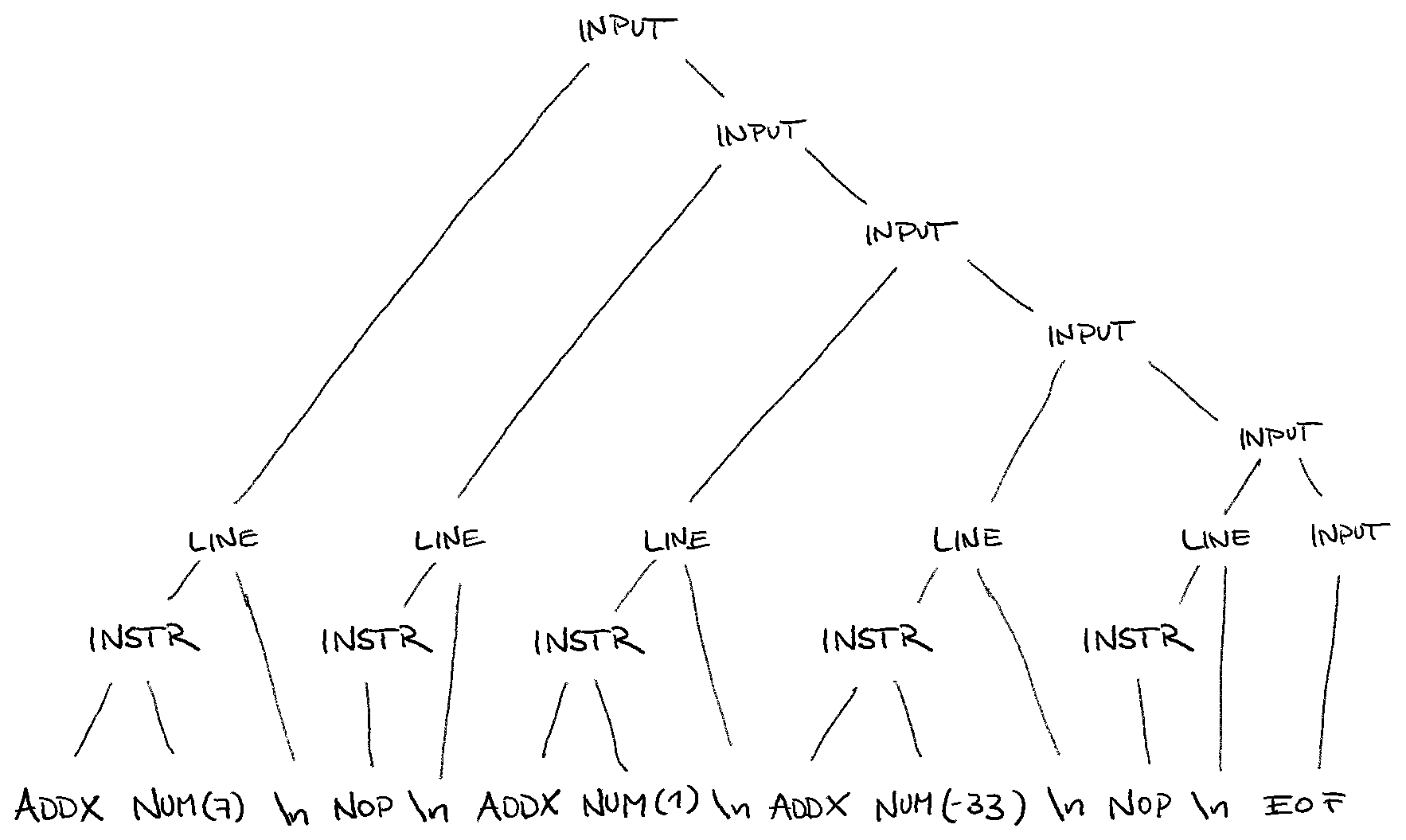
Lessons Learned
By doing this seemingly stupid challenge, I realized that what I was doing was actually not too different from what you’d normally do in the advent of code. The parser framework just gives you the right set of tools to reason about the input (in the most cases, for some tasks it felt very forced). So in a sense, using the parser infrastructure produces code that is a lot cleaner. Also, writing the grammar rules was rather easy, as the tasks for each day are usually just a textual representation of the grammar.
Not all things can be solved during the parse, though. A notable example for this is the challenge of day 8 which requires you to compute some properties on a square full of trees. Here, most of the leg work has to be done after the parse as reasoning over the complete data structure is necessary.
Overall, it was a very fun experience to do this challenge (once I discarded the idea of doing it in C++, of course). It refreshed a lot of things I learned in the Compiler Construction lecture and was unconventional. I’m looking forward to the next (i.e., this) year!
-
I faintly remember a PHP-only challenge, though I couldn’t find the code for it. On the other hand it’s scientifically proven that peoples’ subconsciousness erases traumatic memories. ↩︎
-
That’s how solutions to Advent of Code challenges usually look, you enter a short string produced by your solution. ↩︎
-
Fun Fact: Replacing the
;at the end of a line with the identically-looking greek question mark is a commonly referred prank among programmers. However, this will lead to a syntax error as the character can’t be processed by the lexer. Take that, pranksters. ↩︎ -
For actual programming languages, these grammars are quite complex. In our case however, the individual grammars for each day’s tasks are rather simple. ↩︎
-
Actually,
bisonwas written by Robert Corbett. Richard Stallman just made it compatible to another parser generator namedyacc. ↩︎ -
In case you weren’t aware, a parser is indeed used in most shells to disambiguate what part of your input is program invocation and what are meta-operations like I/O-redirections or pipes.
bashin fact is a whole scripting language and your prompt a mere interpreter. ↩︎ -
A Look-Ahead Left-to-Right parser, constructing a rightmost derivation, using 1 lookahead token. I know that’s a lot to take in, especially if you’re not familiar with it, so let’s keep things simple. ↩︎
-
I omitted the definition of parser arguments for the sake of simplicity, but that is not so difficult. ↩︎

